For many years now, Unified Modeling Language has been widely considered dead and/or irrelevant for C++ software development, especially post-C++11. On the other hand, several high quality open source frameworks for rendering UML (or at least quasi-UML) diagrams are continuously developed and maintained such as PlantUML or MermaidJS, which could potentially be used for visualizing and documenting C++ code bases.
But can these tools still be useful for modern C++ with its lambda expressions, partial template specializations, modules and concepts? Well, in this post I will try to convince you that yes, they can! In particular, I will focus on 3 main areas where automatically generated UML diagrams can be applicable in C++ software development cycle:
- documenting code
- analyzing code
- refactoring
The main premise is that UML can still be useful, provided that the diagrams are generated automatically from code and are easily kept up to date along with an evolving code base. For this purpose I developed a tool based on Clang called clang-uml. In the rest of this post I will try to show how diagrams generated using clang-uml can be useful in modern C++ development.
Table of contents
Open Table of contents
- Motivation and rationale
clang-umloverview- What
clang-umlcan do? - Example use cases
- Visualizing class context
- Visualizing template specializations
- Visualizing template meta-programming code
- Tracking code structure changes in code
- Visualizing design patterns
- Visualizing sequence diagrams in C code
- Visualizing component dependencies
- Calculating code statistics based on JSON generator
- Conclusions
- P.S. Development history
Motivation and rationale
The main idea behind clang-uml is to automate generation of up-to-date, readable diagrams within a C++ code-base as well as document legacy code, based on a single configuration file, which can be stored alongside .clang-format and .clang-tidy.
clang-uml enables declarative specification of the scope of each diagram, in order to ensure that it’s easy to create small, readable diagrams that cover only a specific aspect of the codebase, and can be easily viewed on a web page or included in documentation.
The key feature of clang-uml, which enables this are diagram filters. They allow to fine tune the scope of each diagram, and thus provide you with a several small, but readable diagrams instead of a single huge diagram that cannot be effectively browsed, printed or included in an online documentation of your project. Diagram filters provide means to explicitly state, which elements of the code should be included in the diagram and which won’t, based on their name, namespace, source location, relationship to other elements and many more.
clang-uml overview
-
clang-umlsupports the following diagram types:- class diagrams - including enums, templates, concepts and ObjectiveC interfaces
- sequence diagrams - including lambda expressions, condition statements (including
if constexpr), template functions, CUDA calls and ObjectiveC messages - package diagrams - where packages can be based on namespaces, directories or C++20 modules
- include diagrams - include graph diagrams
-
clang-umlcan generate diagrams in PlantUML, MermaidJS, GraphML and JSON formats -
clang-umlsupports C, C++ (up to C++20) and ObjectiveC -
clang-umlis open-source, Apache 2.0 licensed, available on GitHub -
clang-umlworks on Linux, macos and Windows -
clang-umluses a rather conventional than strict approach to UML, mostly focused on readability and features, which are supported by open-source diagramming tools such as PlantUML or MermaidJS, or to paraphrase a certain Caribbean entrepreneur:

What clang-uml can do?
All diagrams in this post were generated using
clang-umlversion0.6.0from actual C++ code, available from this repository and this repository.
First let’s go through some basic examples of types of diagrams that clang-uml can generate and see how it’s YAML-based configuration file looks like.
Class diagrams
Basic class diagram
Let’s start with the most trivial classical UML example - a class diagram with inheritance. Consider the following code:
namespace basic_class {
/// \brief This is class A
class A {
public:
/// Abstract foo_a
virtual void foo_a() = 0;
/// Abstract foo_c
virtual void foo_c() = 0;
};
/// \brief This is class B
class B : public A {
public:
void foo_a() override { }
};
class C : public A {
public:
void foo_c() override { }
};
/// This is class D
/// which is a little like B
/// and a little like C
class D : public B, public C {
public:
/**
* Forward foo_a
*/
void foo_a() override { }
/**
* Forward foo_c
*/
void foo_c() override { }
private:
/// Pointer to A
A *as;
};
class E : virtual public B, public virtual C {
public:
/// Forward foo_a
void foo_a() override { }
/// Forward foo_c
void foo_c() override { }
private:
/// Pointer to A
A *as;
};
} // namespace basic_class
Now let’s create the definition for this diagram in .clang-uml config file:
compilation_database_dir: debug
output_directory: diagrams
diagrams:
basic_example:
type: class
title: Basic class diagram example
glob:
- basic_example.cpp
using_namespace: basic_class
This very basic config tells clang-uml that we want to generate a class diagram called basic_example with a title "Basic class diagram example", based on a single translation unit basic_example.cpp and whose all diagram element names should be rendered relative to namespace basic_class.
Now run clang-uml with PlantUML generator (which is default) and convert the generated PlantUML source to an SVG image:
clang-uml -n basic_example
plantuml -tsvg diagrams/basic_example.puml
and the result is:
This is fine, but what about all the comments in the code? Let’s extend the diagram config a little bit:
basic_example_with_comments:
type: class
title: Basic class diagram example
comment_parser: clang
glob:
- basic_example.cpp
using_namespace: basic_class
plantuml:
after:
- '{% set e=element("A") %} note left of {{ e.alias }} : {{ trim(e.comment.brief.0) }}'
- '{% set e=element("basic_class::B") %} note top of {{ e.alias }} : {{ trim(e.comment.brief.0) }}'
- |
note right of {{ alias("D") }}
{{ comment("D").text }}
end note
Here, we’re telling clang-uml to add at the end (after) of generated PlantUML source a sequence of lines, where each line can contain some Jinja template that will be rendered to actual text by clang-uml based on diagram context.
And here is the diagram with comments:
Smart pointer relationships
In the previous example you may have noticed association relationships based on raw pointers - but we don’t really use those any more, right? So how about relationships from smart pointers:
#include <memory>
namespace smart_pointers {
class A { };
class B { };
class C { };
class R {
public:
std::unique_ptr<A> a;
std::shared_ptr<B> b;
std::weak_ptr<C> c;
};
} // namespace smart_pointers
with the following config:
smart_pointer_relationships_with_std:
type: class
glob:
- smart_pointer_relationships.cpp
using_namespace: smart_pointers
The generated diagram looks as follows:
Well, ok, but I don’t really want std classes in my diagram, I just want to see relationships between classes in my codebase. Let’s tell clang-uml that:
smart_pointer_relationships:
type: class
glob:
- smart_pointer_relationships.cpp
using_namespace: smart_pointers
include: # <--
namespaces: # <--
- smart_pointers # <--
The include object defines a filter on the intermediate model, which tells clang-uml to only render entities which belong to smart_pointers namespace.
Much better!
Template specialization relationships
Now, with modern C++ we should be using inheritance less and less, so can we use UML to visualize template relationsihps somehow? Sure:
#include <algorithm>
#include <array>
#include <map>
#include <string>
#include <variant>
#include <vector>
namespace template_specializations {
template <typename T, typename... Ts> class A {
T value;
std::variant<Ts...> values;
};
template <int... Is> class B {
std::array<int, sizeof...(Is)> ints;
};
template <typename T, int... Is> class C {
std::array<T, sizeof...(Is)> ints;
};
class R {
A<int, std::string, float> a1;
A<int, std::string, bool> a2;
B<3, 2, 1> b1;
B<1, 1, 1, 1> b2;
C<std::map<int, std::vector<std::vector<std::vector<std::string>>>>, 3, 3,
3>
c1;
};
} // namespace template_specializations
Just add a diagram config:
template_specializations:
type: class
glob:
- template_specializations.cpp
using_namespace: template_specializations
include:
namespaces:
- template_specializations
and here is the diagram:
Dashed arrows in the diagram represent template specialization/instantiation relationships. In official UML terminology this is actually called
template binding, but let’s not go there…
Concepts
With the introduction of concepts in C++20, non-virtual polymorphism can be used much, much easier and clang-uml supports visualization of concept constraint relationships. Consider the following non-virtual polymorphism example:
#include <string>
namespace concepts {
template <typename T>
concept fruit_c = requires(T t) {
T{};
t.get_name();
};
template <typename T>
concept apple_c = fruit_c<T> && requires(T t) { t.get_sweetness(); };
template <typename T>
concept orange_c = fruit_c<T> && requires(T t) { t.get_bitterness(); };
class gala_apple {
public:
auto get_name() const -> std::string { return "gala"; }
auto get_sweetness() const -> float { return 0.8; }
};
class empire_apple {
public:
auto get_name() const -> std::string { return "empire"; }
auto get_sweetness() const -> float { return 0.6; }
};
class lima_orange {
public:
auto get_name() const -> std::string { return "lima"; }
auto get_bitterness() const -> float { return 0.8; }
};
class valencia_orange {
public:
auto get_name() const -> std::string { return "valencia"; }
auto get_bitterness() const -> float { return 0.6; }
};
template <apple_c TA, orange_c TO> class fruit_factory {
public:
auto create_apple() const -> TA { return TA{}; }
auto create_orange() const -> TO { return TO{}; }
};
using fruit_factory_1 = fruit_factory<gala_apple, valencia_orange>;
using fruit_factory_2 = fruit_factory<empire_apple, lima_orange>;
struct R {
fruit_factory_1 factory_1;
fruit_factory_2 factory_2;
};
} // namespace concepts
and the following config:
concepts:
type: class
glob:
- concepts.cpp
using_namespace: concepts
include:
namespaces:
- concepts
which produce the following diagram:
In the diagram we can see how each factory conforms to the same interface fruit_c through concept constraints, which are rendered with the same arrows as dependencies but contain the name of constrained parameter.
Class diagram with packages
If we want to add a little more structure to class diagrams, we can group the diagram elements into packages based on one of the following:
- namespaces
- directories
- C++20 modules
Let’s try to create a class diagram with packages from C++20 modules:
simple_app/src/simple_app_mod.cppm:
export module simple_app;
export import :frontend_lib;
export import :frontend_lib.webview;
export import :frontend_lib.desktop;
export import :backend_lib;
simple_app/src/backend_lib.cppm:
export module simple_app:backend_lib;
export namespace simple_app::backend {
class Backend {
public:
};
} // namespace simple_app::backend
simple_app/src/frontend_lib.cppm:
export module simple_app:frontend_lib;
export namespace simple_app::frontend {
namespace detail {
enum class Style { light, dark };
} // namespace detail
class Frontend {
public:
detail::Style style;
};
} // namespace simple_app::frontend
simple_app/src/webview.cppm:
export module simple_app:frontend_lib.webview;
import :frontend_lib;
export namespace simple_app::frontend {
class Webview : public Frontend { };
} // namespace simple_app::frontend
simple_app/src/desktop.cppm:
export module simple_app:frontend_lib.desktop;
import :frontend_lib;
export namespace simple_app::frontend {
class Desktop : public Frontend { };
} // namespace simple_app::frontend
simple_app/simple_app.cpp:
import simple_app;
#include <memory>
namespace simple_app {
class App {
public:
std::unique_ptr<frontend::Frontend> frontend;
std::unique_ptr<backend::Backend> backend;
int run() { return 0; }
};
} // namespace simple_app
Now let’s add the following config:
class_with_modules_packages:
type: class
glob:
- simple_app/simple_app.cpp
generate_packages: true
package_type: module
using_module: simple_app
using_namespace: simple_app
include:
paths:
- simple_app
This config tells clang-uml to generate a class diagram, which includes packages based on C++20 modules, the module names should be rendered relative to simple_app module and only include elements defined in simple_app subdirectory. And the diagram looks like this:
Note that
clang-umlautomatically divides the package name in subpackages based on slices (:), as well as.(although the latter has no representation in the standard and is only a convention)
Sequence diagrams
Another useful type of UML diagrams are sequence diagrams, which represent interactions between participants (e.g. classes) as sequences of messages originating from activities (bodies of functions or methods) to other functions or methods.
Of course, a complete sequence diagram of even a medium size application would be of very little use and would be very difficult to browse. clang-uml provides a mechanism for specifying boundary conditions for sequence diagrams in the following form:
from- generate sequence diagram originating at specific activity (e.g. a function)to- generate sequence diagram of all call chains ending in a specific activityfrom_to- generate all call chains which start and end at a specific activity (useful to figure out for example how do I get from methodA::a()to methodZ::z())
In addition to these conditions, standard inclusion and exclusion filters also work allowing to further limit the size of the diagram by removing for instance private methods, specific namespaces, etc.
Basic sequence diagram
Let’s try to visualize the following code:
namespace basic_sequence {
struct A {
void a(int i = 10)
{
if (i > 0)
a(i - 1);
}
void b(int i = 10) { c(i); }
void c(int i) { d(i); }
void d(int i)
{
if (i > 0)
b(i - 1);
else
a();
}
};
void tmain()
{
A a;
a.a();
a.b();
}
} // namespace basic_sequence
The configuration file will have one starting condition from:
basic_sequence:
type: sequence
glob:
- basic_sequence.cpp
using_namespace: basic_sequence
include:
namespaces:
- basic_sequence
from:
- function: "basic_sequence::tmain()"
and the resulting diagram looks like this:
Nothing too fancy, one interesting thing here is that recursive calls do not generate infinite call chain, but are repeated only once (a(int)).
More complex sequence diagram
Let’s try with a little more complex sequence diagram, a sketch of a simple communication stack using nested template specializations for setting up the message handling sequence:
#include <atomic>
#include <functional>
#include <iostream>
#include <memory>
#include <string>
namespace advanced_sequence {
std::string encode_b64(std::string &&content) {
return std::move(content); }
template <typename T> class Encoder : public T {
public:
bool send(std::string &&msg) {
return T::send(std::move(
// Encode the message using Base64 encoding
// and pass it to the next layer
encode(std::move(msg))));
}
protected:
std::string encode(std::string &&msg) {
return encode_b64(std::move(msg));
}
};
template <typename T> class Retrier : public T {
public:
bool send(std::string &&msg) {
std::string buffer{std::move(msg)};
int retryCount = 5;
// Repeat until send() succeeds or retry
// count is exceeded
while (retryCount--) {
if (T::send(buffer))
return true;
}
return false;
}
};
class ConnectionPool {
public:
void connect() {
if (!is_connected_.load())
connect_impl();
}
bool send(const std::string &msg) { return true; }
private:
void connect_impl() { is_connected_ = true; }
std::atomic<bool> is_connected_;
};
int tmain() {
auto pool = std::make_shared<Encoder<Retrier<ConnectionPool>>>();
// Establish connection to the remote server synchronously
pool->connect();
// Repeat for each line in the input stream
for (std::string line; std::getline(std::cin, line);) {
if (!pool->send(std::move(line)))
break;
}
return 0;
}
} // namespace advanced_sequence
and the following config file:
advanced_sequence:
type: sequence
glob:
- advanced_sequence.cpp
include:
namespaces:
- advanced_sequence
exclude:
access:
- private
using_namespace: advanced_sequence
from:
- function: advanced_sequence::tmain()
generate_message_comments: true
generate_condition_statements: true
participants_order:
- advanced_sequence::tmain()
- advanced_sequence::Encoder<advanced_sequence::Retrier<advanced_sequence::ConnectionPool>>
- advanced_sequence::Retrier<advanced_sequence::ConnectionPool>
- advanced_sequence::ConnectionPool
- advanced_sequence::encode_b64(std::string &&)
The config file includes some additional elements, most notably an exclude filter, which tells clang-uml to skip all private methods as well as participants_order list, which allows us to adjust the order to the sequence participants in the final diagram (although usually the default order is just fine). Also, this time we want to include condition statements (generate_condition_statements: true) as well as any comments preceding call expressions (generate_message_comments: true). This produces the following diagram:
Here the benefit of sequence diagrams is I think rather obvious. In one small diagram we can see not only all generated template instantiations, but also which of them handle which calls and in what order when sending a message.
Package diagrams
Sometimes we’re interested in a more high level view of the codebase structure, which can be reflected in a package diagram, especially if it contains dependencies between the packages. Similarly to packages in class diagrams, clang-uml can generate the package diagrams from namespaces, directories and C++20 modules.
Namespace dependencies
Let’s see what it looks like for a namespace package diagram:
#include <array>
#include <map>
#include <memory>
#include <string>
#include <vector>
namespace namespace_package {
namespace A::AA {
namespace A1 {
struct CA { };
}
namespace A2 {
template <typename T> struct CB {
T cb;
};
}
namespace A3 {
struct CC { };
}
namespace A4 {
struct CD { };
}
namespace A5 {
struct CE { };
}
namespace A6 {
struct CF { };
}
namespace A7 {
struct CG { };
}
namespace A8 {
struct CH { };
}
namespace A9 {
struct CI { };
}
namespace A10 {
struct CJ { };
}
namespace A11 {
struct CK { };
}
namespace A12 {
struct CL { };
}
namespace A13 {
struct CM { };
}
namespace A14 {
struct CN { };
}
namespace A15 {
struct CO { };
}
namespace A16 {
struct CP { };
}
namespace A17 {
struct CR { };
}
namespace A18 {
enum class S { s1, s2, s3 };
}
}
namespace B::BB::BBB {
class CBA : public A::AA::A6::CF {
public:
A::AA::A1::CA *ca_;
A::AA::A2::CB<int> cb_;
std::shared_ptr<A::AA::A3::CC> cc_;
std::map<std::string, std::unique_ptr<A::AA::A4::CD>> *cd_;
std::array<A::AA::A15::CO, 5> co_;
static A::AA::A16::CP *cp_;
CBA() = default;
CBA(A::AA::A14::CN *cn) { }
friend A::AA::A17::CR;
template <typename... Item> CBA(std::tuple<Item...> &items) { }
void ce(const std::vector<A::AA::A5::CE> /*ce_*/) { }
std::shared_ptr<A::AA::A7::CG> cg() { return {}; }
template <typename T>
void ch(std::map<T, std::shared_ptr<A::AA::A8::CH>> &ch_)
{
}
template <typename T>
std::map<T, std::shared_ptr<A::AA::A9::CI>> ci(T * /*t*/)
{
return {};
}
A::AA::A18::S s;
};
void cj(std::unique_ptr<A::AA::A10::CJ> /*cj_*/) { }
}
} // namespace namespace_package
with the following config:
namespace_package:
type: package
glob:
- namespace_package.cpp
include:
namespaces:
- namespace_package
using_namespace: namespace_package
produces the following diagram:
The dashed arrows represent package dependencies (in this case namespace dependencies), i.e. an arrow from B::BB::BBB to A::AA::A1 means that some class in B::BB::BBB uses some declaration from A::AA::A1 (in this case it’s A::AA::A1::CA).
Relationship lines are actually links to source code on GitHub, you can click on them and you should get to the respective line in the code.
This type of diagram can be very useful in larger code bases, where you want to maintain a strict separation of concerns between components. By having this diagram generated as part of CI we can continuously monitor whether some unwanted dependencies haven’t crept in into the code.
Include diagrams
Finally, clang-uml can also generate include dependency graph diagrams.
Simple include graph diagram
Let’s consider a very simple code spread over a few files:
include_diagram/include/include1.h:
#pragma once
#include "lib1/lib1.h"
#include <yaml-cpp/yaml.h>
#include <string>
namespace basic_include {
int foo() { return lib1::foo2(); }
} // namespace basic_include
include_diagram/include/lib1/lib1.h:
#pragma once
namespace basic_include::lib1 {
int foo2() { return 0; }
} // namespace basic_include::lib1
include_diagram/src/include_diagram.cpp:
#include "../include/include1.h"
namespace basic_include {
} // namespace basic_include
The config file for this diagram looks like this:
basic_include:
type: include
glob:
- src/include_diagram.cpp
generate_system_headers: true
relative_to: include_diagram
include:
paths:
- .
The generate_system_headers tells clang-uml to also show system header files (included using angle brackets) directly included by project code, render paths relative to include_diagram subdirectory and only include files in that subdirectory (except for the system headers). The resulting diagram looks as follows:
Dashed arrows represent system includes, regular arrows represent internal includes.
Diagram filters
As I mentioned at the beginning, diagram filters are the key feature of clang-uml, enabling declarative specification of each diagram scope in a way that on the one hand enables describing what the diagram should contain, but on the other hand is flexible enough so that it doesn’t have to be updated too often as code evolves.
Filters can be specified separately for each diagram, and they can be added as either include or exclude filters, depending on which is more appropriate for a given diagram.
Filters can be defined in 2 modes:
- basic
- advanced
The basic (and default) mode is much simpler and usually sufficient. The include filters tell clang-uml to only include in the diagram elements, which match the predicates, and exclude filter tells clang-uml to additionally remove from those some subset of elements.
This however has it’s limitations, for instance it is not possible to specify that you want to exclude std namespace, but include at the same time std::thread class. In order to achieve this the advanced mode has to be used, which provides logical operators anyof and allof to create more complex filtering logic.
Some examples of diagram filters are presented below.
Inheritance diagram of all subclasses of class ns1::A
diagrams:
A_inheritance_diagram:
type: class
glob: ['*.cc']
using_namespace: ns1
include:
subclasses:
- ns1::A
relationships:
- inheritance
Dependency diagram of all dependencies and dependants of class ns1::A
diagrams:
A_inheritance_diagram:
type: class
glob: ['*.cc']
using_namespace: ns1
include:
dependencies:
- ns1::A
dependants:
- ns1::A
Diagram of all elements in a direct or indirect relationship with ns1::A (up to a radius of 2)
diagrams:
A_inheritance_diagram:
type: class
glob: ['*.cc']
using_namespace: ns1
include:
context:
- match:
radius: 2
pattern: ns1::A
Advanced diagram filter inclusion with subclasses and namespaces
advanced_filter_diagram:
type: class
filter_mode: advanced
glob: ['*.cc']
include_system_headers: true
include:
allof:
namespaces:
- ns1
- std
context:
- match:
radius: 2
pattern: A
exclude:
anyof:
access:
- private
- public
- protected
relationships:
- dependency
For more examples see the test cases of clang-uml, which are documented here. For each test case there is the diagram configuration, source code and generated diagrams included on each test page.
Example use cases
Below are a few examples of how clang-uml can help visualize various aspects of actual C++ or C code.
Visualizing class context
Let’s try to create a class context diagram for LLVM Clang class clang::comments::Parser. A context diagram in clang-uml for a class contains all elements, which are in some relationship to the context root. In general we can provide a radius, which will include all elements reachable from the root by N relations, but for now let’s use the default which is 1.
The following config:
clang_comment_parser_context_full:
type: class
glob:
- clang/lib/AST/CommentParser.cpp
using_namespace: clang
include:
namespaces:
- clang
context:
- clang::comments::Parser
produces the following diagram:
That is not very readable. Let’s try to make this a little less cluttered:
clang_comments_parser_context_small:
type: class
glob:
- clang/lib/AST/CommentParser.cpp
using_namespace: clang
include:
namespaces:
- clang
context:
- clang::comments::Parser
exclude: # <---
access: [public, protected, private] # <---
relationships: # <---
- dependency # <---
and the resulting diagram is much nicer:
Visualizing template specializations
In some cases it can be helpful to see how template specialization are dependent on each other, however it is not always obvious from the code. Consider the following contrived example:
#include <map>
#include <string>
namespace deduced_context {
template <typename T> struct A;
template <typename U> struct A<U &> {
U &u;
};
template <typename U> struct A<std::map<std::string, U> &> {
U &u;
};
template <>
struct A<std::map<std::string, std::map<std::string, std::string>> &> { };
template <typename U> struct A<U **> {
U **u;
};
template <typename U> struct A<U **const *> {
U ***u;
};
template <typename U> struct A<U const *const volatile> {
U ***u;
};
template <typename U> struct A<U &&> {
U &&u;
};
template <typename U> struct A<U const &> {
U const &u;
};
template <typename M, typename C> struct A<M C::*> {
C &c;
M C::*m;
};
template <typename M, typename C> struct A<M C::*&&> {
C &&c;
M C::*m;
};
template <typename M, typename C, typename Arg> struct A<M (C::*)(Arg)> {
C &c;
M C::*m;
};
} // namespace deduced_context
with the following config:
deduced_context:
type: class
glob:
- deduced_context.cpp
include:
namespaces:
- deduced_context
using_namespace: deduced_context
plantuml:
before:
- left to right direction
and the result is:
In this diagram we can immediately see the dependencies between specific template specialization of the A<T> template, based on deduced context.
Visualizing template meta-programming code
Another use case for UML diagrams can be related to template meta-programming. Let’s try to visualize using clang-uml a simple type list implementation:
#include <iostream>
#include <type_traits>
/// Based on recursive-types-through-inheritance example from:
/// https://www.scs.stanford.edu/~dm/blog/param-pack.html
namespace recursive_list {
template <typename... T> struct HList;
template <> struct HList<> {
static constexpr bool isEmpty() noexcept { return true; }
};
template <typename T0, typename... TRest>
struct HList<T0, TRest...> : HList<TRest...> {
using head_type = T0;
using tail_type = HList<TRest...>;
static constexpr bool isEmpty() noexcept { return false; }
[[no_unique_address]] head_type value_{};
constexpr HList() = default;
template <typename U0, typename... URest>
constexpr HList(U0 &&u0, URest &&...urest)
: tail_type(std::forward<URest>(urest)...)
, value_(std::forward<U0>(u0)) { }
head_type &head() & { return value_; }
const head_type &head() const & { return value_; }
head_type &&head() && { return value_; }
tail_type &tail() & { return *this; }
const tail_type &tail() const & { return *this; }
tail_type &&tail() && { return *this; }
};
template <typename... T> HList(T...) -> HList<T...>;
template <typename T>
concept IsArithmetic = std::is_arithmetic_v<T>;
template <IsArithmetic... T> struct Arithmetic : HList<T...> {
using HList<T...>::HList;
public:
constexpr double sum() const { return sumImpl(*this); }
private:
static constexpr double seed() { return 100.0; }
template <typename L> static constexpr double sumImpl(const L &list) {
if constexpr (L::isEmpty()) {
return seed();
} else {
return static_cast<double>(list.head()) + sumImpl(list.tail());
}
}
};
int tmain() {
constexpr Arithmetic<int, float, double> a{11, 12, 13};
return a.sum();
}
} // namespace recursive_list
Let’s create 2 diagrams from this code, a class diagram and a sequence diagram:
type_list_class:
type: class
glob:
- type_list.cpp
using_namespace: type_list
include:
namespaces:
- type_list
type_list_sequence:
type: sequence
glob:
- type_list.cpp
using_namespace: type_list
include:
namespaces:
- type_list
from:
- function: "type_list::tmain()"
type_list_class:
One interesting thing here is how equivalent template specializations are represented, i.e. with circular template instantiation relationship between HList<T...> and HList<TRest...>. These templates represent the same exact type, but in the code they occur in different places with different names for the template parameter. The rationale for this is that it’s less confusing when we track their relationships visually. In the future there might be a configuration option to merge these into just one diagram element (e.g. just HList<T...>).
type_list_sequence:
Even though the calls happen in release build at compile time they are still included in the sequence diagram.
This diagram shows how variadic pack recursion works in practice, i.e. each consecutive call is performed on a template instantiation based on the TRest... of the previous pack expansion until we get to a template instantiation with no types (yes, I know it’s obvious - but maybe not necessarily to someone who is just learning template metaprogramming). One more thing worth mentioning here, is that the if constexpr statement cannot be rendered here as alt block, because each if constexpr branch is actually in a different method.
Tracking code structure changes in code
For this example let’s use a popular C++ library facebook/folly by Meta. Out of various useful utils in the library we’ll try to visualize the evolution of folly::Executor class hierarchy across various revisions. In order not to repeat the diagram definition for each revision, we’ll use yet another clang-uml feature - diagram templates:
compilation_database_dir: debug
output_directory: diagrams
# Add some compile flags to compilation database to make Clang happy
add_compile_flags:
- -Wno-unknown-warning-option
- -Wno-nullability-completeness
- -march=x86-64
# Add links to the code on GitHub
generate_links:
link:
.: https://github.com/facebook/folly/blob/{{ git.commit }}/{{ element.source.path }}#L{{ element.source.line }}
diagram_templates:
# Diagram template for executor class hierarchy
executors_class_diagram_tmpl:
type: class
description: Template for folly::Executor class hierarchy
template: |
"executors_class_diagram_{{ version }}":
type: class
title: "'folly::Executor' class hierarchy diagram {{ version }}"
glob:
- folly/executors/*.cpp
using_namespace:
- folly
include:
subclasses:
- folly::Executor
relationships:
- inheritance
namespaces:
- folly
paths:
- folly/executors
- folly/Executor.h
exclude:
namespaces:
- folly::detail
access: [public, protected, private]
plantuml:
before:
- left to right direction
To automate the process of checking out specific folly revision and generating compile_commands.json we can use the following script:
#!/bin/bash
clang_uml_bin=~/devel/clang-uml/debug/src/clang-uml
# Some hand picked tags
tags=(
v2020.03.16.00
v2022.03.14.00
v2024.03.18.00
)
# Generate a diagram for each selected Git tag
for tag in ${tags[@]}; do
echo "Generating diagram for tag $tag"
git checkout $tag
cmake -S . -B debug -DCMAKE_EXPORT_COMPILE_COMMANDS=ON -DCMAKE_BUILD_TYPE=Release
$clang_uml_bin --generate-from-template executors_class_diagram_tmpl --template-var version=$tag
done
# Generate SVG diagrams from PlantUML sources
plantuml -tsvg diagrams/*.puml
Executing the script produces the following diagrams:
v2020.03.16.00:
v2022.03.14.00:
v2024.03.18.00:
Visualizing design patterns
Another useful feature of UML diagrams is visualizing design patterns in code. In practice, this can be very handy when we know a certain part of the code was written according to some design pattern, but with time that neatly constructed code can easily ‘evolve’ into something else entirely. One way to keep that in check is to generate a diagram for that piece of code as part of CI and verify between PR’s whether the code structure still resembles the intended design pattern.
Let’s consider a more modern variant of the classic visitor pattern, which doesn’t use virtual methods but templates and CRTP (Curiously Recurring Template Pattern):
#include <iostream>
#include <string>
namespace nonvirtual_visitor_pattern {
template <typename Derived> struct Visitable {
template <typename Visitor> void accept(Visitor &v) {
v.visit(static_cast<Derived &>(*this));
}
};
struct Foo : public Visitable<Foo> {
int fooValue{0xF00};
};
struct Bar : public Visitable<Bar> {
std::string barValue{"BAR"};
};
struct PrintVisitor {
void visit(Foo &foo) {
std::cout << "Visiting Foo: " << foo.fooValue << std::endl;
}
void visit(Bar &bar) {
std::cout << "Visiting Bar: " << bar.barValue << std::endl;
}
};
int tmain() {
Foo foo;
Bar bar;
PrintVisitor visitor;
foo.accept(visitor);
bar.accept(visitor);
return 0;
}
} // namespace nonvirtual_visitor_pattern
First let’s generate a class diagram using the following config:
nonvirtual_visitor_pattern:
type: class
glob:
- nonvirtual_visitor_pattern.cpp
using_namespace: nonvirtual_visitor_pattern
include:
namespaces:
- nonvirtual_visitor_pattern
the diagram looks like this:
and also a sequence diagram just in case:
nonvirtual_visitor_pattern_sequence:
type: sequence
glob:
- nonvirtual_visitor_pattern.cpp
using_namespace: nonvirtual_visitor_pattern
include:
namespaces:
- nonvirtual_visitor_pattern
from:
- function: "nonvirtual_visitor_pattern::tmain()"
Now with every refactoring, or addition of new visited types we can check visually whether the code still resembles a visitor pattern at least to some extent.
Visualizing sequence diagrams in C code
Sequence diagrams were originally designed as a means for visualizing message passing between participants in a system. In C++, participants are simply classes and messages are the method calls, but what participants can we have in plain C? clang-uml supports actually 2 types of participants in C code:
- functions - each function is a separate participant
- files - each file is a participant and functions declared in that file (header or source) are activities
Visualizing calls originating from a specific function
Let’s try to visualize some function sequence graph for cURL library, in particular it’s easy interface.
We’ll try to visualize call sequence originating from curl_easy_send(...). The config for the diagram can look like this:
curl_easy_send_full:
type: sequence
title: "'curl_easy_send' sequence diagram"
glob:
include: [lib/**/*.c]
exclude: [lib/mprintf.c]
include:
paths: [lib/,include/curl]
combine_free_functions_into_file_participants: true
generate_message_comments: true
message_comment_width: 50
generate_condition_statements: true
from:
- function: "curl_easy_send(CURL *,const void *,size_t,size_t *)"
The glob pattern includes all translation units from lib directory except for mprintf.c (which generates a lot of uninteresting calls). The resulting diagram looks like this:
This is not too big as far as sequence diagrams go - especially if opened in a separate browser window - but we can notice that there are several uninteresting calls (related to some list and hashmap handling). Let’s try to skip them using additional exclude patterns in glob:
curl_easy_send:
type: sequence
title: "'curl_easy_send' sequence diagram"
glob:
include: [lib/**/*.c]
exclude: [lib/mprintf.c, lib/hash.c, lib/llist.c] # <--
include:
paths: [ lib/, include/curl ]
combine_free_functions_into_file_participants: true
generate_message_comments: true
message_comment_width: 50
generate_condition_statements: true
from:
- function: "curl_easy_send(CURL *,const void *,size_t,size_t *)"
and we get a nicely reduced diagram:
Hint: message names in the diagram are actually hyperlinks, clicking them will redirect you to the relevant
cURLsource code line on GitHub.
From this diagram we can see straight away, the complete chain of calls and files involved in performing this operation, instead of navigating manually through our IDE’s Go to... functionality (oh, so cURL inhibits SIGPIPE signals when performing actual send…).
Visualizing function usage in a code base
Another use for sequence diagrams can be to discover how a specific method or function is used within a code base, i.e. where the calls to this function originate and what is the sequence of calls that end in this function. For example, let’s see how cURL’s Curl_conn_send(...) function is used. For this we have to create a diagram config without the starting from condition, but instead the diagram will have an end condition to:
curl_conn_send_usage:
type: sequence
title: "'Curl_conn_send' usage sequence diagram"
glob:
include: [lib/**/*.c]
exclude: [tests/libtest/*.c, lib/mprintf.c, lib/hash.c, lib/llist.c]
include:
paths: [ lib/, include/curl ]
combine_free_functions_into_file_participants: true
generate_message_comments: true
message_comment_width: 50
generate_condition_statements: true
to:
- function: "Curl_conn_send(struct Curl_easy *,int,const void *,size_t,_Bool,size_t *)"
Unfortunately, this function is quite popular in the cURL codebase and the resulting diagram is too big to show in a blog post (but you can open it here).
Let’s however assume that for some reason we’re only interested in the calls to this function that originate somewhere in the mqtt API of cURL. We can specify a from_to condition which binds sequences from both sides, but in this case we won’t specify a concrete starting point, but we’ll use a regular expression to say that we’re interested in any function whose name starts with mqtt_:
curl_conn_send_usage_in_mqtt:
type: sequence
title: "'Curl_conn_send' usage in mqtt API sequence diagram"
glob:
include: [lib/**/*.c]
exclude: [tests/libtest/*.c, lib/mprintf.c, lib/hash.c, lib/llist.c]
include:
paths: [ lib/, include/curl ]
combine_free_functions_into_file_participants: true
generate_message_comments: true
message_comment_width: 50
generate_condition_statements: true
from_to:
- - function:
r: "mqtt_.*"
- function: "Curl_conn_send(struct Curl_easy *,int,const void *,size_t,_Bool,size_t *)"
and the resulting diagram is below:
The diagram shows there are 5 different ways the Curl_conn_send() is called from the mqtt interface. Since this diagram doesn’t visualize function activities, only call paths across the code, it doesn’t have any activity lifelines.
This diagram has been generated on a specific platform (x86_64, release mode, Linux, single thread, etc…). With different configuration options the diagram could look different so if necessary make sure you generate diagrams using
compile_commands.jsonfor all relevant targets in your build system.
Visualizing component dependencies
Now let’s consider another issue in large code bases, that is of interdependencies among application components. Typically large code base is structured in some way, either through namespaces, directories, submodules or today C++20 modules.
As the code evolves, dependencies between individual components often tend to increase, as it’s just easier and faster to directly use another component functionality when needed instead of abstracting that dependency away.
One way to tackle this is to maintain an up-to-date dependency graph, which can be used to visually or algorithmically detect unwanted dependencies and raise a red flag during a pull request.
For this example, let’s try to use some bigger C++ project, for instance one that is in top 5 C++ project on GitHub (at least according to this ranking) - Godot.
Godot developers are not very big on C++ namespaces, all code seems to be in root namespace, fortunately it is neatly structured into a filesystem hierarchy, so we’ll use subdirectories to represent packages in the diagrams. First we have to prepare the compilation_database.json:
git clone https://github.com/godotengine/godot && cd godot
git checkout 4.3-stable
scons platform=linuxbsd compiledb=true compile_commands.json
$ jq length compile_commands.json
2305
2305 translation units to work with - ok. Let’s prepare the .clang-uml config for a package diagram based on directory structure. We can reduce the number of translation units that need to be processed by specifying in glob which parts of the code we’re really interested in:
compilation_database_dir: .
output_directory: ../diagrams
add_compile_flags:
- -Wno-deprecated-builtins
- -Wno-unknown-warning-option
- -Wno-unused-but-set-variable
- -Wno-ordered-compare-function-pointers
- -mno-sse
generate_links:
link: 'https://github.com/godotengine/godot/blob/{{ git.commit }}/{{ element.source.path }}#L{{ element.source.line }}'
tooltip: '{% if existsIn(element, "comment") and existsIn(element.comment, "brief") %}{{ abbrv(trim(replace(element.comment.brief.0, "\n+", " ")), 256) }}{% else %}{{ element.name }}{% endif %}'
diagrams:
godot_package_diagram:
type: package
package_type: directory
glob:
- core/**/*.cpp
- drivers/**/*.cpp
- editor/**/*.cpp
- main/**/*.cpp
- misc/**/*.cpp
- modules/**/*.cpp
- scene/**/*.cpp
- servers/**/*.cpp
include:
paths:
- .
Now, this took some tinkering to get right, especially with respect to additional compile flags that were required by Clang to parse the entire codebase, however now we can generate the diagram. To change things a little, instead of generating PlantUML we will generate GraphML graph:
$ clang-uml -n godot_package_diagram -g graphml -p
Processing translation units and generating diagrams:
godot_package_...[███████████████████████████████████] [31m:24s] 951/951 ✔
Done
951 translation units and ~30 minutes later we have the diagram.
Currently each diagram is generated in a single thread, so we are processing 951 translation one by one while building the intermediate diagram model. However multiple diagrams can be generated at the same time on separate threads.
In order to convert the GraphML into SVG, we’ll use yED graph editor. yED allows to load any valid GraphML document, but since GraphML doesn’t have a standard way of encoding labels or URL’s in the graph, we have to also load a custom properties mapping file: clang-uml.cnfx - more detailed instructions are here. Finally we can run one of many available layout algorithms in yED and we get the diagram:
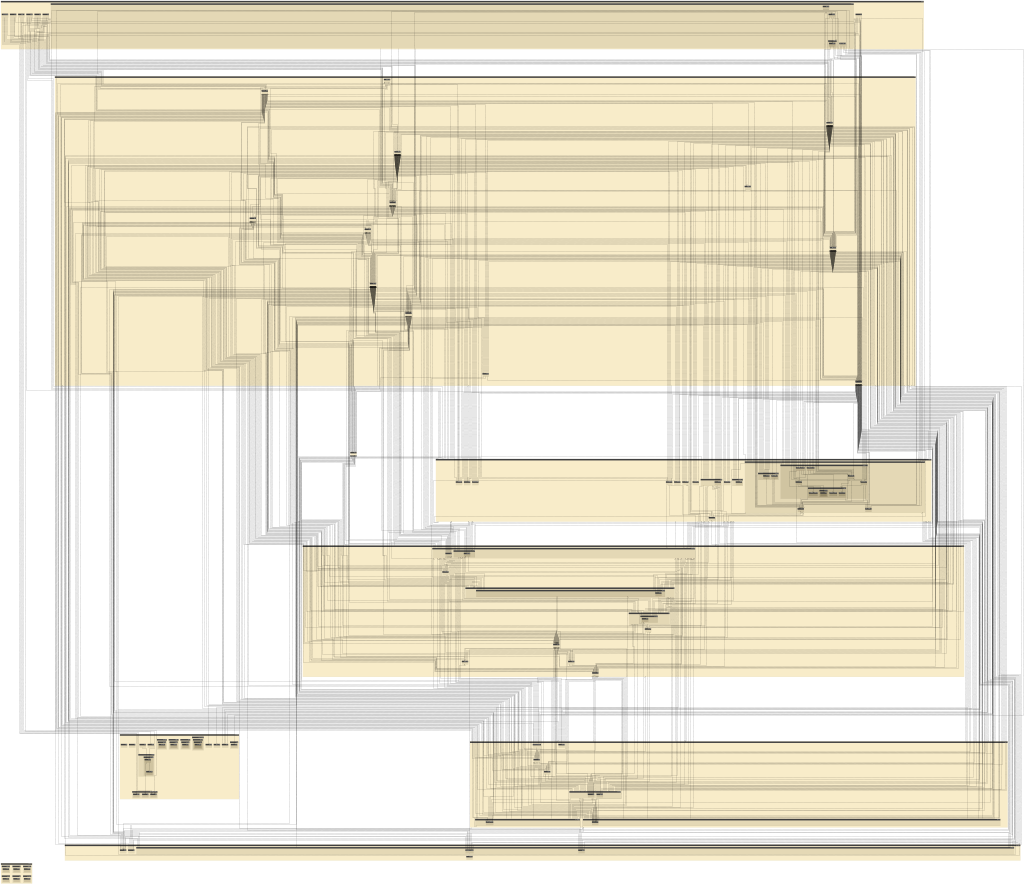
The diagram above is just a PNG, the full SVG can be downloaded here and the GraphML source here.
Well, unless you’re a hardcore Factorio fan, this diagram is probably not very interesting. But fortunately we can use diagram filters to focus on a specific aspect of the code. Let’s say we’re responsible for the core/crypto component, and we want to know all components that directly depend on it as well as components that core/crypto directly depends on:
diagrams:
godot_package_diagram:
type: package
package_type: directory
glob:
- core/**/*.cpp
- drivers/**/*.cpp
- editor/**/*.cpp
- main/**/*.cpp
- misc/**/*.cpp
- modules/**/*.cpp
- scene/**/*.cpp
- servers/**/*.cpp
include:
paths:
- .
context:
- "core/crypto"
And the result is:
Thanks to the generate_links option in the config file, the relationships in the SVG diagram are also links to locations in source code on GitHub, from which they originate, so for instance if you’re interested why scene/main component depends on core/crypto just click the respective dependency line (or here).
Calculating code statistics based on JSON generator
Another generator supported by clang-uml is JSON generator. This generator, instead of generating PlantUML or MermaidJS, dumps the internal diagram model representation into a JSON document. This can be useful for things like custom documentation generation, code statistics, code search or even generating diagrams in some other tools.
Let’s try to generate some statistics for yaml-cpp open-source library, using clang-uml JSON generator, excluding detail namespace:
all_class:
type: class
title: All classes diagram
glob:
- src/*.cpp
include:
namespaces:
- YAML
exclude:
namespaces:
- YAML::detail
In case of class diagram, the JSON document contains basically a list of elements and a list of relationships between these elements. Let’s see what some random element looks like:
cat all_class.json | jq '.elements[10]'
{
"bases": [],
"display_name": "NodeType",
"id": "11971162833605890825",
"is_abstract": false,
"is_nested": false,
"is_struct": true,
"is_template": false,
"is_union": false,
"members": [],
"methods": [],
"name": "NodeType",
"namespace": "YAML",
"source_location": {
"column": 8,
"file": "include/yaml-cpp/node/type.h",
"line": 11,
"translation_unit": "src/memory.cpp"
},
"template_parameters": [],
"type": "class"
}
Some more examples of things we can find out from the JSON output are:
- names of all enums in the code
$ cat all_class.json | jq '.elements[] | select(.type|test("enum")) | .display_name'
"YAML::REGEX_OP"
"YAML::Stream::CharacterSet"
"YAML::EmitterStyle::value"
"YAML::NodeType::value"
"YAML::Node::Zombie"
"YAML::Token::STATUS"
"YAML::Token::TYPE"
"YAML::Scanner::IndentMarker::INDENT_TYPE"
"YAML::Scanner::IndentMarker::STATUS"
"YAML::Scanner::FLOW_MARKER"
"YAML::CHOMP"
"YAML::ACTION"
"YAML::FOLD"
"YAML::Tag::TYPE"
"YAML::UtfIntroState"
"YAML::UtfIntroCharType"
"YAML::EmitFromEvents::State::value"
"YAML::EmitterNodeType::value"
"YAML::EMITTER_MANIP"
"YAML::_Tag::Type::value"
"YAML::FmtScope::value"
"YAML::GroupType::value"
"YAML::FlowType::value"
"YAML::StringFormat::value"
"YAML::StringEscaping::value"
"YAML::CollectionType::value"
- number of all classes:
$ cat all_class.json | jq '.elements[] | select(.type|test("class")) | .display_name' | wc -l
127
- all method names of a specific class:
$ cat all_class.json | jq '.elements[] | select(.display_name|test("YAML::Node")) | .methods[] | select(.name) | .name'
"NodeEvents"
"NodeEvents"
"NodeEvents"
"operator="
"operator="
"Emit"
"Setup"
"Emit"
"IsAliased"
"AliasManager"
"RegisterReference"
"LookupAnchor"
"_CreateNewAnchor"
- number of relationships of specific type
$ cat all_class.json | jq '.relationships[] | select(.type|test("extension")) | .source' | wc -l
21
$ cat all_class.json | jq '.relationships[] | select(.type|test("instantiation")) | .source' | wc -l
51
Conclusions
In this blog post I tried to present a case for usefulness of diagrams generated from existing C++ code (not the other way round!). And while I do believe that in the end the source code should be the final source of truth, reading it doesn’t have to be the only way to understand the code, especially on high level.
In terms of the functionality provided by clang-uml, the above examples are by far exhaustive, a more detailed list of feature can be found here. Another way to see all the features is to browse through the test cases documentation here, which is a byproduct of the clang-uml test suite that is executed on very build.
P.S. Development history
Below is a brief history of how clang-uml evolved over the last 3 years.
0.1.X
- Based on
libclang - Only class diagrams supported
- Very limited template relationship support, mostly due to unexposed template arguments in
libclang:- Manually parsing C++ templates is were I personally draw the line…
0.2.X
- Discovered cppast - beautiful C++ API to libclang
- More template arguments information available
- Unfortunately
cppastwas still based onlibclang - No API for call expression traversal to enable sequence diagrams
- FYI,
cppastis currently in EOL
0.3.X - 0.5.X
- Switched to Clang LibTooling
- Full access to AST unlocked
- Added actual sequence diagrams, and also package and include diagrams
- Added C++20 features including concepts, modules and coroutines
0.6.X
- Added GraphML generators
—

{kind=link}
{kind=link}